ANSYS Fluent¶
ANSYS Fluent software contains the broad physical modeling capabilities needed to model flow, turbulence, heat transfer, and reactions for industrial applications ranging from air flow over an aircraft wing to combustion in a furnace, from bubble columns to oil platforms, from blood flow to semiconductor manufacturing, and from clean room design to wastewater treatment plants. Special models that give the software the ability to model in-cylinder combustion, aeroacoustics, turbomachinery, and multiphase systems have served to broaden its reach.
Common Way to Run Fluent¶
To run ANSYS Fluent in a batch mode, you can utilize/modify the default fluent.slurm script and execute it via the sbatch command:
#!/bin/bash
#SBATCH --nodes=5 # Request 5 nodes
#SBATCH --ntasks-per-node=128 # 128 MPI processes per node
#SBATCH --job-name=ANSYS-test # Job name
#SBATCH --partition=qcpu # Partition name
#SBATCH --account=ACCOUNT_ID # Account/project ID
#SBATCH --output=%x-%j.out # Output log file with job name and job ID
#SBATCH --time=04:00:00 # Walltime
#!change the working directory (default is home directory)
#cd <working directory> (working directory must exists)
DIR=/scratch/project/PROJECT_ID/$SLURM_JOB_ID
mkdir -p "$DIR"
cd "$DIR" || exit
echo Running on host `hostname`
echo Time is `date`
echo Directory is `pwd`
echo This jobs runs on the following processors:
echo $SLURM_NODELIST
#### Load ansys module so that we find the cfx5solve command
ml ANSYS/2023R2-intel-2022.12
# Count the total number of cores allocated
NCORES=$SLURM_NTASKS
fluent 3d -t$NCORES -cnf=$SLURM_NODELIST -g -i fluent.jou
SVS FEM recommends utilizing sources by keywords: nodes, ppn. These keywords allows addressing directly the number of nodes (computers) and cores (ppn) utilized in the job. In addition, the rest of the code assumes such structure of allocated resources.
A working directory has to be created before sending the job into the queue.
The input file should be in the working directory or a full path to the input file has to be specified.
The input file has to be defined by a common Fluent journal file
which is attached to the Fluent solver via the -i fluent.jou parameter.
A journal file with the definition of the input geometry and boundary conditions and defined process of solution has, for example, the following structure:
/file/read-case aircraft_2m.cas.gz
/solve/init
init
/solve/iterate
10
/file/write-case-dat aircraft_2m-solution
/exit yes
The appropriate dimension of the problem has to be set by a parameter (2d/3d).
Fast Way to Run Fluent From Command Line¶
fluent solver_version [FLUENT_options] -i journal_file -slurm
This syntax will start the ANSYS FLUENT job under Slurm using the sbatch commnad.
When resources are available, Slurm will start the job and return the job ID, usually in the form of _job_ID.hostname_.
This job ID can then be used to query, control, or stop the job using standard Slurm commands, such as squeue or scancel.
The job will be run out of the current working directory and all output will be written to the fluent.o _job_ID_ file.
Running Fluent via User's Config File¶
If no command line arguments are present, the sample script uses a configuration file called slurm_fluent.conf. This configuration file should be present in the directory from which the jobs are submitted (which is also the directory in which the jobs are executed). The following is an example of what the content of slurm_fluent.conf can be:
input="example_small.flin"
case="Small-1.65m.cas"
fluent_args="3d -pmyrinet"
outfile="fluent_test.out"
mpp="true"
The following is an explanation of the parameters:
input is the name of the input file.
case is the name of the .cas file that the input file will utilize.
fluent_args are extra ANSYS FLUENT arguments. As shown in the previous example, you can specify the interconnect by using the -p interconnect command. The available interconnects include ethernet (default), Myrinet, InfiniBand, Vendor, Altix, and Crayx. MPI is selected automatically, based on the specified interconnect.
outfile is the name of the file to which the standard output will be sent.
mpp="true" will tell the job script to execute the job across multiple processors.
To run ANSYS Fluent in batch mode with the user's config file, you can utilize/modify the following script and execute it via the sbatch command:
#!/bin/sh
#SBATCH --nodes=2 # Request 2 nodes
#SBATCH --ntasks-per-node=4 # 4 MPI processes per node
#SBATCH --cpus-per-task=128 # 128 CPUs (threads) per MPI process
#SBATCH --job-name=$USE-Fluent-Project # Job name
#SBATCH --partition=qprod # Partition name
#SBATCH --account=XX-YY-ZZ # Account/project ID
#SBATCH --output=%x-%j.out # Output file name with job name and job ID
#SBATCH --time=04:00:00 # Walltime
cd $SLURM_SUBMIT_DIR
#We assume that if they didn’t specify arguments then they should use the
#config file if ["xx${input}${case}${mpp}${fluent_args}zz" = "xxzz" ]; then
if [ -f slurm_fluent.conf ]; then
. slurm_fluent.conf
else
printf "No command line arguments specified, "
printf "and no configuration file found. Exiting n"
fi
fi
#Augment the ANSYS FLUENT command line arguments case "$mpp" in
true)
#MPI job execution scenario
num_nodes=‘$SLURM_NODELIST | sort -u | wc -l‘
cpus=‘expr $num_nodes * $NCPUS‘
#Default arguments for mpp jobs, these should be changed to suit your
#needs.
fluent_args="-t${cpus} $fluent_args -cnf=$SLURM_NODELIST"
;;
*)
#SMP case
#Default arguments for smp jobs, should be adjusted to suit your
#needs.
fluent_args="-t$NCPUS $fluent_args"
;;
esac
#Default arguments for all jobs
fluent_args="-ssh -g -i $input $fluent_args"
echo "---------- Going to start a fluent job with the following settings:
Input: $input
Case: $case
Output: $outfile
Fluent arguments: $fluent_args"
#run the solver
fluent $fluent_args > $outfile
It runs the jobs out of the directory from which they are submitted (SLURM_SUBMIT_DIR).
Running Fluent in Parralel¶
Fluent could be run in parallel only under the Academic Research license. To do this, the ANSYS Academic Research license must be placed before the ANSYS CFD license in user preferences. To make this change, the anslic_admin utility should be run:
/ansys_inc/shared_les/licensing/lic_admin/anslic_admin
The ANSLIC_ADMIN utility will be run:
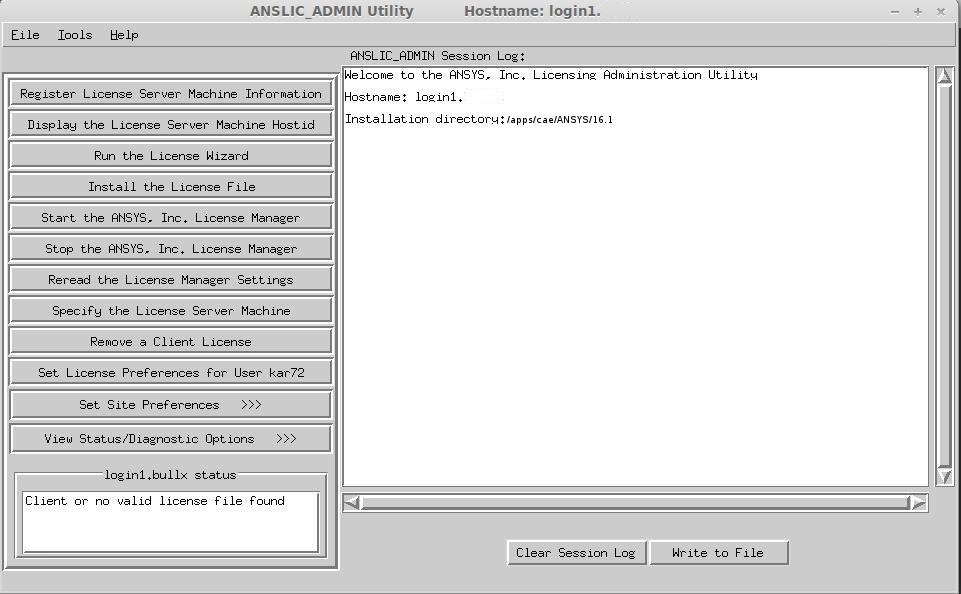
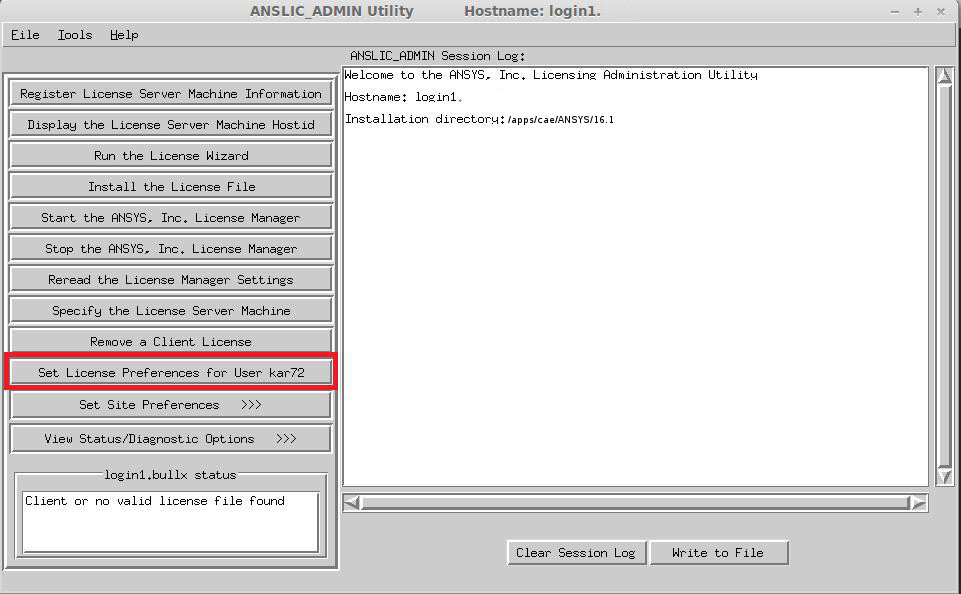
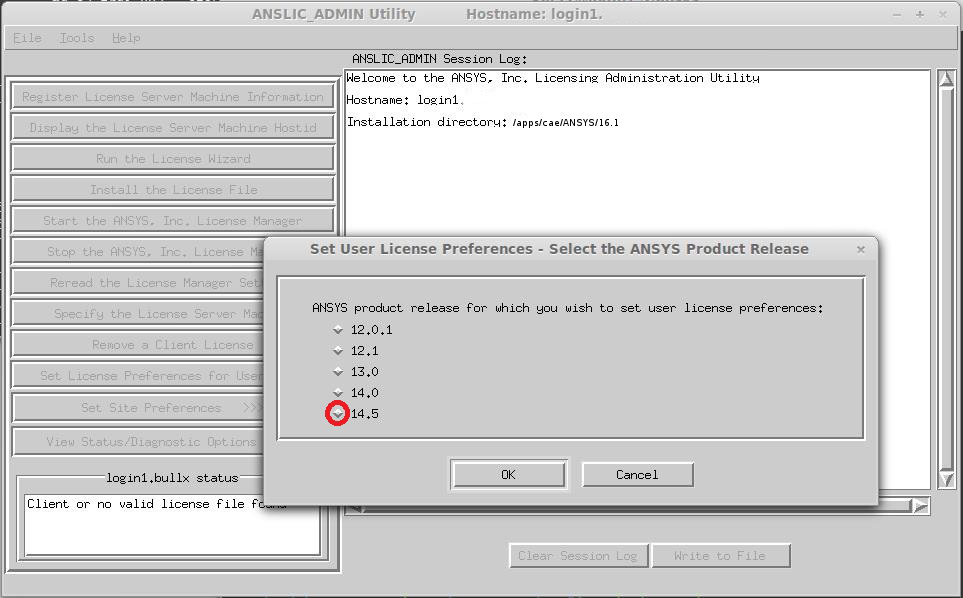
The ANSYS Academic Research license should be moved up to the top of the list: