Heterogeneous Memory Management on Intel Platforms¶
Partition p10-intel offser heterogeneous memory directly exposed to the user. This allows to manually pick appropriate kind of memory to be used at process or even single allocation granularity. Both kinds of memory are exposed as memory-only NUMA nodes. This allows both coarse (process level) and fine (allocation level) grained control over memory type used.
Overview¶
At the process level the numactl facilities can be utilized, while Intel provided memkind library allows for finer control. Both memkind library and numactl can be accessed by loading memkind module or OpenMPI module (only numactl).
ml memkind
Process Level (NUMACTL)¶
The numactl allows to either restrict memory pool of the process to specific set of memory NUMA nodes
numactl --membind <node_ids_set>
or select single preffered node
numactl --preffered <node_id>
where <node_ids_set> is comma separated list (eg. 0,2,5,...) in combination with ranges (such as 0-5). The membind option kills the process if it requests more memory than can be satisfied from specified nodes. The preffered option just reverts to using other nodes according to their NUMA distance in the same situation.
Convenient way to check numactl configuration is
numactl -s
which prints configuration in its execution environment eg.
numactl --membind 8-15 numactl -s
policy: bind
preferred node: 0
physcpubind: 0 1 2 ... 189 190 191
cpubind: 0 1 2 3 4 5 6 7
nodebind: 0 1 2 3 4 5 6 7
membind: 8 9 10 11 12 13 14 15
The last row shows allocations memory are restricted to NUMA nodes 8-15.
Allocation Level (MEMKIND)¶
The memkind library (in its simplest use case) offers new variant of malloc/free function pair, which allows to specify kind of memory to be used for given allocation. Moving specific allocation from default to HBM memory pool then can be achieved by replacing:
void *pData = malloc(<SIZE>);
/* ... */
free(pData);
with
#include <memkind.h>
void *pData = memkind_malloc(MEMKIND_HBW, <SIZE>);
/* ... */
memkind_free(NULL, pData); // "kind" parameter is deduced from the address
Similarly other memory types can be chosen.
Note
The allocation will return NULL pointer when memory of specified kind is not available.
High Bandwidth Memory (HBM)¶
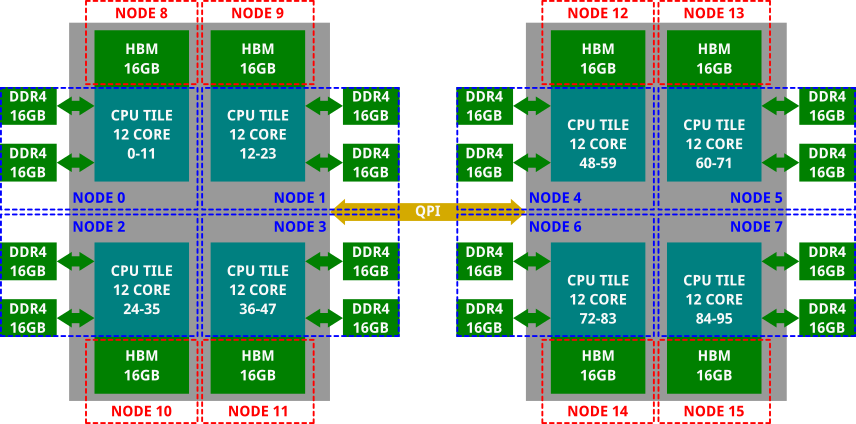
Intel Sapphire Rapids (partition p10-intel) consists of two sockets each with 128GB of DDR and 64GB on-package HBM memory. The machine is configured in FLAT mode and therefore exposes HBM memory as memory-only NUMA nodes (16GB per 12-core tile). The configuration can be verified by running
numactl -H
which should show 16 NUMA nodes (0-7 should contain 12 cores and 32GB of DDR DRAM, while 8-15 should have no cores and 16GB of HBM each).
Process Level¶
With this we can easily restrict application to DDR DRAM or HBM memory:
# Only DDR DRAM
numactl --membind 0-7 ./stream
# ...
Function Best Rate MB/s Avg time Min time Max time
Copy: 369745.8 0.043355 0.043273 0.043588
Scale: 366989.8 0.043869 0.043598 0.045355
Add: 378054.0 0.063652 0.063483 0.063899
Triad: 377852.5 0.063621 0.063517 0.063884
# Only HBM
numactl --membind 8-15 ./stream
# ...
Function Best Rate MB/s Avg time Min time Max time
Copy: 1128430.1 0.015214 0.014179 0.015615
Scale: 1045065.2 0.015814 0.015310 0.016309
Add: 1096992.2 0.022619 0.021878 0.024182
Triad: 1065152.4 0.023449 0.022532 0.024559
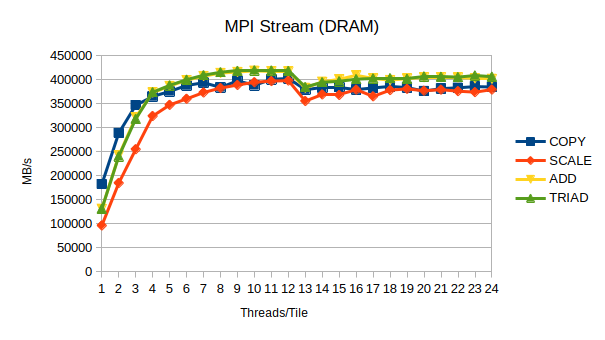
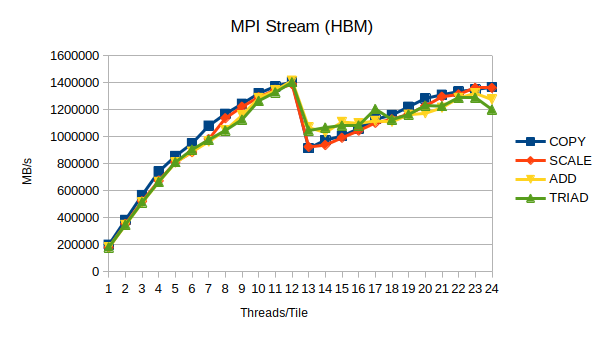
The DDR DRAM achieves bandwidth of around 400GB/s, while the HBM clears 1TB/s bar.
Some further improvements can be achieved by entirely isolating a process to a single tile. This can be useful for MPI jobs, where $OMPI_COMM_WORLD_RANK can be used to bind each process individually. The simple wrapper script to do this may look like
#!/bin/bash
numactl --membind $((8 + $OMPI_COMM_WORLD_RANK)) $@
and can be used as
mpirun -np 8 --map-by slot:pe=12 membind_wrapper.sh ./stream_mpi
(8 tiles with 12 cores each). However, this approach assumes 16GB of HBM memory local to the tile is sufficient for each process (memory cannot spill between tiles). This approach may be significantly more useful in combination with --preferred instead of --membind to force preference of local HBM with spill to DDR DRAM. Otherwise
mpirun -n 8 --map-by slot:pe=12 numactl --membind 8-15 ./stream_mpi
is most likely preferable even for MPI workloads. Applying above approach to MPI Stream with 8 ranks and 1-24 threads per rank we can expect these results:
Allocation Level¶
Allocation level memory kind selection using memkind library can be illustrated using modified stream benchmark. The stream benchmark uses three working arrays (A, B and C), whose allocation can be changed to memkind_malloc as follows
#include <memkind.h>
// ...
STREAM_TYPE *a = (STREAM_TYPE *)memkind_malloc(MEMKIND_HBW_ALL, STREAM_ARRAY_SIZE * sizeof(STREAM_TYPE));
STREAM_TYPE *b = (STREAM_TYPE *)memkind_malloc(MEMKIND_REGULAR, STREAM_ARRAY_SIZE * sizeof(STREAM_TYPE));
STREAM_TYPE *c = (STREAM_TYPE *)memkind_malloc(MEMKIND_HBW_ALL, STREAM_ARRAY_SIZE * sizeof(STREAM_TYPE));
// ...
memkind_free(NULL, a);
memkind_free(NULL, b);
memkind_free(NULL, c);
Arrays A and C are allocated from HBM (MEMKIND_HBW_ALL), while DDR DRAM (MEMKIND_REGULAR) is used for B.
The code then has to be linked with memkind library
gcc -march=native -O3 -fopenmp -lmemkind memkind_stream.c -o memkind_stream
and can be run as
export MEMKIND_HBW_NODES=8,9,10,11,12,13,14,15
OMP_NUM_THREADS=$((N*12)) OMP_PROC_BIND=spread ./memkind_stream
While the memkind library should be able to detect HBM memory on its own (through HMAT and hwloc) this is not supported on p10-intel. This means that NUMA nodes representing HBM have to be specified manually using MEMKIND_HBW_NODES environment variable.
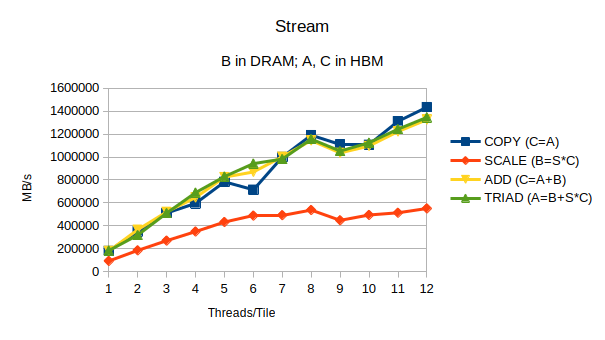
With this setup we can see that simple copy operation (C[i] = A[i]) achieves bandwidth comparable to the application bound entirely to HBM memory. On the other hand the scale operation (B[i] = s*C[i]) is mostly limited by DDR DRAM bandwidth. Its also worth noting that operations combining all three arrays are performing close to HBM-only configuration.
Simple Application¶
One of applications that can greatly benefit from availability of large slower and faster smaller memory is computing histogram with many bins over large dataset.
#include <iostream>
#include <vector>
#include <chrono>
#include <cmath>
#include <cstring>
#include <omp.h>
#include <memkind.h>
const size_t N_DATA_SIZE = 2 * 1024 * 1024 * 1024ull;
const size_t N_BINS_COUNT = 1 * 1024 * 1024ull;
const size_t N_ITERS = 10;
#if defined(HBM)
#define DATA_MEMKIND MEMKIND_REGULAR
#define BINS_MEMKIND MEMKIND_HBW_ALL
#else
#define DATA_MEMKIND MEMKIND_REGULAR
#define BINS_MEMKIND MEMKIND_REGULAR
#endif
int main(int argc, char *argv[])
{
const double binWidth = 1.0 / double(N_BINS_COUNT + 1);
double *pData = (double *)memkind_malloc(DATA_MEMKIND, N_DATA_SIZE * sizeof(double));
size_t *pBins = (size_t *)memkind_malloc(BINS_MEMKIND, N_BINS_COUNT * omp_get_max_threads() * sizeof(double));
#pragma omp parallel
{
drand48_data state;
srand48_r(omp_get_thread_num(), &state);
#pragma omp for
for(size_t i = 0; i < N_DATA_SIZE; ++i)
drand48_r(&state, &pData[i]);
}
auto c1 = std::chrono::steady_clock::now();
for(size_t it = 0; it < N_ITERS; ++it)
{
#pragma omp parallel
{
for(size_t i = 0; i < N_BINS_COUNT; ++i)
pBins[omp_get_thread_num()*N_BINS_COUNT + i] = size_t(0);
#pragma omp for
for(size_t i = 0; i < N_DATA_SIZE; ++i)
{
const size_t idx = size_t(pData[i] / binWidth) % N_BINS_COUNT;
pBins[omp_get_thread_num()*N_BINS_COUNT + idx]++;
}
}
}
auto c2 = std::chrono::steady_clock::now();
#pragma omp parallel for
for(size_t i = 0; i < N_BINS_COUNT; ++i)
{
for(size_t j = 1; j < omp_get_max_threads(); ++j)
pBins[i] += pBins[j*N_BINS_COUNT + i];
}
std::cout << "Elapsed Time [s]: " << std::chrono::duration<double>(c2 - c1).count() << std::endl;
size_t total = 0;
#pragma omp parallel for reduction(+:total)
for(size_t i = 0; i < N_BINS_COUNT; ++i)
total += pBins[i];
std::cout << "Total Items: " << total << std::endl;
memkind_free(NULL, pData);
memkind_free(NULL, pBins);
return 0;
}
Using HBM Memory (P10-Intel)¶
Following commands can be used to compile and run example application above
ml GCC memkind
export MEMKIND_HBW_NODES=8,9,10,11,12,13,14,15
g++ -O3 -fopenmp -lmemkind histogram.cpp -o histogram_dram
g++ -O3 -fopenmp -lmemkind -DHBM histogram.cpp -o histogram_hbm
OMP_PROC_BIND=spread GOMP_CPU_AFFINITY=0-95 OMP_NUM_THREADS=96 ./histogram_dram
OMP_PROC_BIND=spread GOMP_CPU_AFFINITY=0-95 OMP_NUM_THREADS=96 ./histogram_hbm
Moving histogram bins data into HBM memory should speedup the algorithm more than twice. It should be noted that moving also pData array into HBM memory worsens this result (presumably because the algorithm can saturate both memory interfaces).