HyperQueue¶
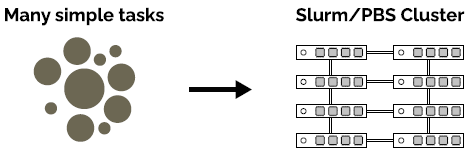
HyperQueue lets you build a computation plan consisting of a large amount of tasks and then execute it transparently over a system like SLURM/PBS. It dynamically groups tasks into Slurm jobs and distributes them to fully utilize allocated nodes. You thus do not have to manually aggregate your tasks into Slurm jobs.
Find more about HyperQueue in its documentation.
Features¶
-
Transparent task execution on top of a Slurm/PBS cluster
-
Automatic task distribution amongst jobs, nodes, and cores
-
Automatic submission of PBS/Slurm jobs
-
Dynamic load balancing across jobs
-
Work-stealing scheduler
- NUMA-aware, core planning, task priorities, task arrays
-
Nodes and tasks may be added/removed on the fly
-
Scalable
-
Low overhead per task (~100μs)
- Handles hundreds of nodes and millions of tasks
-
Output streaming avoids creating many files on network filesystems
-
Easy deployment
-
Single binary, no installation, depends only on libc
- No elevated privileges required
Installation¶
-
On Barbora and Karolina, you can simply load the HyperQueue module:
$ ml HyperQueue -
If you want to install/compile HyperQueue manually, follow the steps on the official webpage.
Usage¶
Starting the Server¶
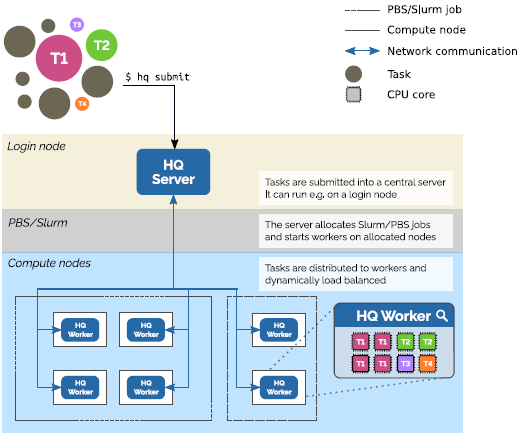
To use HyperQueue, you first have to start the HyperQueue server. It is a long-lived process that is supposed to be running on a login node. You can start it with the following command:
$ hq server start
Submitting Computation¶
Once the HyperQueue server is running, you can submit jobs into it. Here are a few examples of job submissions. You can find more information in the documentation.
-
Submit a simple job (command
echo 'Hello world'in this case)$ hq submit echo 'Hello world' -
Submit a job with 10000 tasks
$ hq submit --array 1-10000 my-script.sh
Once you start some jobs, you can observe their status using the following commands:
# Display status of a single job
$ hq job <job-id>
# Display status of all jobs
$ hq jobs
Important
Before the jobs can start executing, you have to provide HyperQueue with some computational resources.
Providing Computational Resources¶
Before HyperQueue can execute your jobs, it needs to have access to some computational resources. You can provide these by starting HyperQueue workers which connect to the server and execute your jobs. The workers should run on computing nodes, therefore they should be started inside Slurm jobs.
There are two ways of providing computational resources.
-
Allocate Slurm jobs automatically
HyperQueue can automatically submit Slurm jobs with workers on your behalf. This system is called automatic allocation. After the server is started, you can add a new automatic allocation queue using the
hq alloc addcommand:$ hq alloc add slurm -- -A<PROJECT-ID> -p qcpu_expAfter you run this command, HQ will automatically start submitting Slurm jobs on your behalf once some HQ jobs are submitted.
-
Manually start Slurm jobs with HQ workers
With the following command, you can submit a Slurm job that will start a single HQ worker which will connect to a running HQ server.
$ salloc <salloc-params> -- /bin/bash -l -c "$(which hq) worker start"
Tip
For debugging purposes, you can also start the worker e.g. on a login node, simply by running
$ hq worker start. Do not use such worker for any long-running computations though!
Architecture¶
Here you can see the architecture of HyperQueue. The user submits jobs into the server which schedules them onto a set of workers running on compute nodes.